MySQL学习笔记
本文最后更新于:几秒前
MySQL学习
一、MyISAM和InnoDB
MyISAM和InnoDB都是存储引擎
MyISAM是MySQL在5.5以前的默认存储引擎,性能很好,但是不支持事务和行级锁,并且崩溃后无法安全恢复,其索引文件与数据文件分开存储
InnoDB是5.5以后的默认存储引擎,其配合内置的redolog日志实现崩溃后的安全恢复,并且提供事务和行级锁的功能,索引与数据存储在一起
1.一条SQL的具体过程
- 连接:连接数据库,主要验证了用户名和密码以及权限等,一个连接只要不断开,后续的SQL无需多次连接
- 查询缓存:MySQL8以后就移除了,它主要针对
SELECT语句,会缓存一些近期执行过的结果,用来命中重复执行的语句 - 分析:包括词法分析和语法分析
- 优化:根据SQL语句选择数据库任务最优的方式去执行,比如使用什么索引
- 执行:先要再次校验权限,然后再执行
2.更新类SQL的执行(InnoDB)
- a.执行器调用存储引擎更新数据行
- b.存储引擎将数据记入内存中,打印
redolog记录修改内容,并redolog状态为prepare - c.执行器生成
binlog写进磁盘 - d.将
redlog状态成commit3.crash-safe 崩溃安全
MySQL的Server层自带一个日志模块binlog,用来记录每条执行的逻辑语句,因此MySQL可以实现定点时间恢复。而InnoDB引擎在引擎层自带了一个redolog,用来记录每次执行后的物理变化,并有prepare和commit两个状态,因此可以实现崩溃安全恢复。
比如在2中的执行过程中,数据库突然崩溃,有以下情况: - 在a执行后崩溃,
redolog和binlog都没记录,数据不过是内存的脏页,崩溃后对内存做的修改自然不存在 - 在b或c执行后崩溃,
redolog记录为prepare状态,所以会去看binlog中是否有该记录,没有则事务回滚(与undolog有关),有则进行提交,将redlog状态成commit二 、事务
1.事务隔离级别
READ-UNCOMMITTED读取未提交,可能出现脏读、不可重复读、幻读READ-COMMITTED读取已提交,可能出现不可重复读、幻读REPEATABLE-READ可重复读,可能出现幻读SERIALIZABLE可串行化
以上四种事务隔离级别,由低到高,MySQL的默认事务隔离级别是REPEATABLE-READ可重复读
2.脏读,不可重复读,幻读
- 脏读:如果某个事务读取了上个事务还没有提交的数据,如果上个事务发生回滚的话,这个数据就是不正确的数据
- 不可重复读:如果一个事务多次访问同一个数据,但是其他事务在其两次访问的间隙中修改数据的话,则会出翔两次重复访问的数据是不相同的
- 幻读:一个事务要多次查询一些符合特定特定条件的数据,但期间其他事务作了一些新增操作,使得其后面一次查询多出一些数据
三、锁
1.表级锁
MyISAM和InnoDB都支持
在访问某个表的数据时,将整个表都锁住,加锁快,开销小,但是并发性差
2.行级锁
InnoDB支持
只锁住被访问的行,提高并发度,但是加锁慢,开销大,并且可能死锁
3.共享锁和拍他锁
这是锁的底层性质,或者称作读锁或者写锁
- 共享锁:也就是读锁,允许多个事务并发的读取同一个资源,但是不允许修改
- 排他锁:也就是写锁,只允许一个事务对资源进行读或写操作
4.InnoDB的死锁情况
不同于MyISAM,InnoDB的锁是逐行获得的,并且是针对索引展开的,当所有的索引就被命中,行级锁便上升为表级锁,其他情况是逐行上锁的,这样就导致可能出现两个事务互相占用了对方需要的行,从而产生死锁。
解决办法:
- 像解决哲学家进餐那样,用户访问数据约定好统一的访问顺序
- 由InnoDB自己监测出来,让其中一个事务回滚,放弃锁
四、索引
MySQL索引的底层是hash表或者B+Tree,hash表适合单条记录的查询,但是其他操作都不适合,使用较少。
我们重点了解MySQL的底层B+Tree实现
1.什么是B+Tree?
B+Tree就是B+树,是一种树,具有左小右大的特点
1)二叉树:
由根节点开始,每个节点最多一个左子树一个右子树,并且为了达到排序的目的,要求左小右大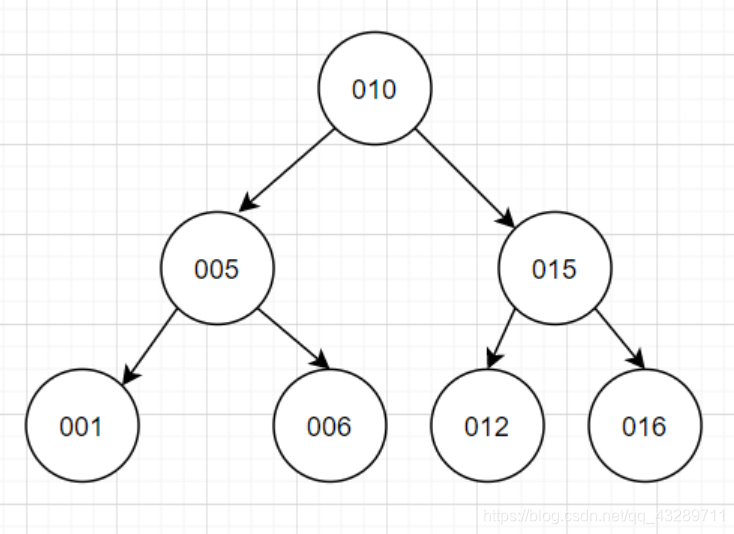
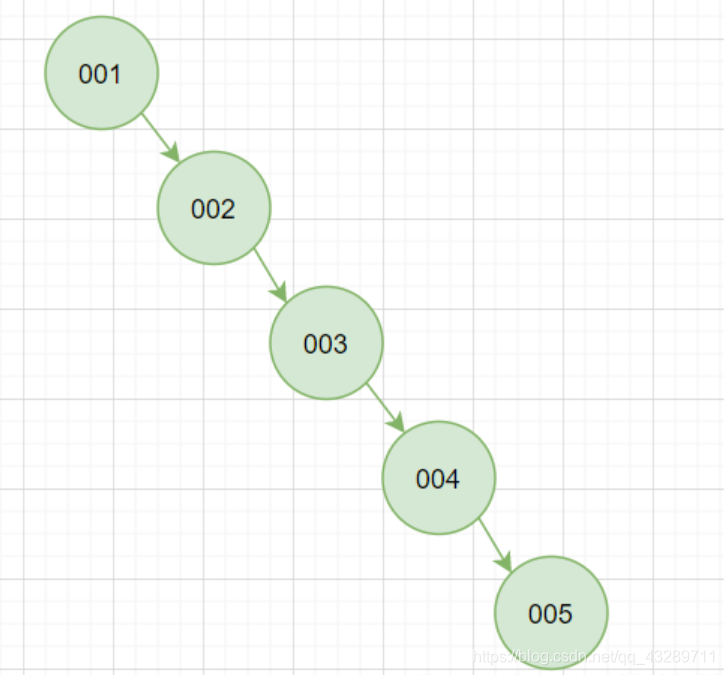
2)平衡二叉树:
左子树和右子树的规模较为平衡,要求左右层数差不能大于1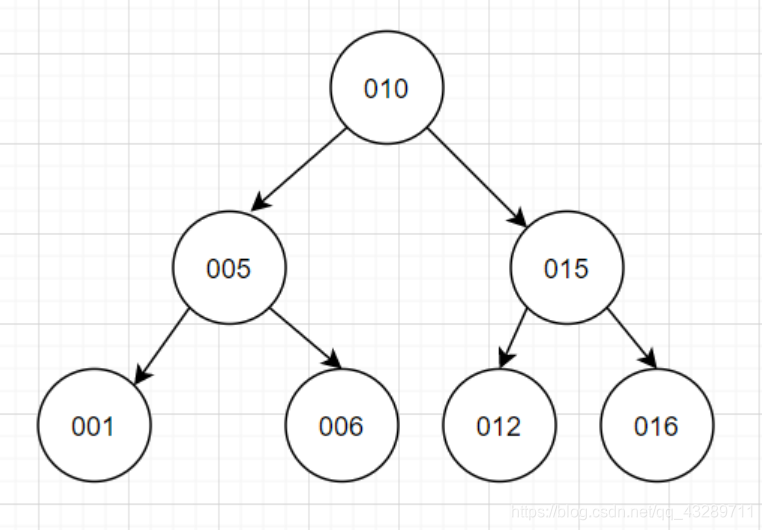
3)B树:
在平衡二叉树的设计基础上,让树不止局限于只有两个子树,让高高瘦瘦的平衡二叉树变成矮胖的多叉树,但依旧左小右大,讲究平衡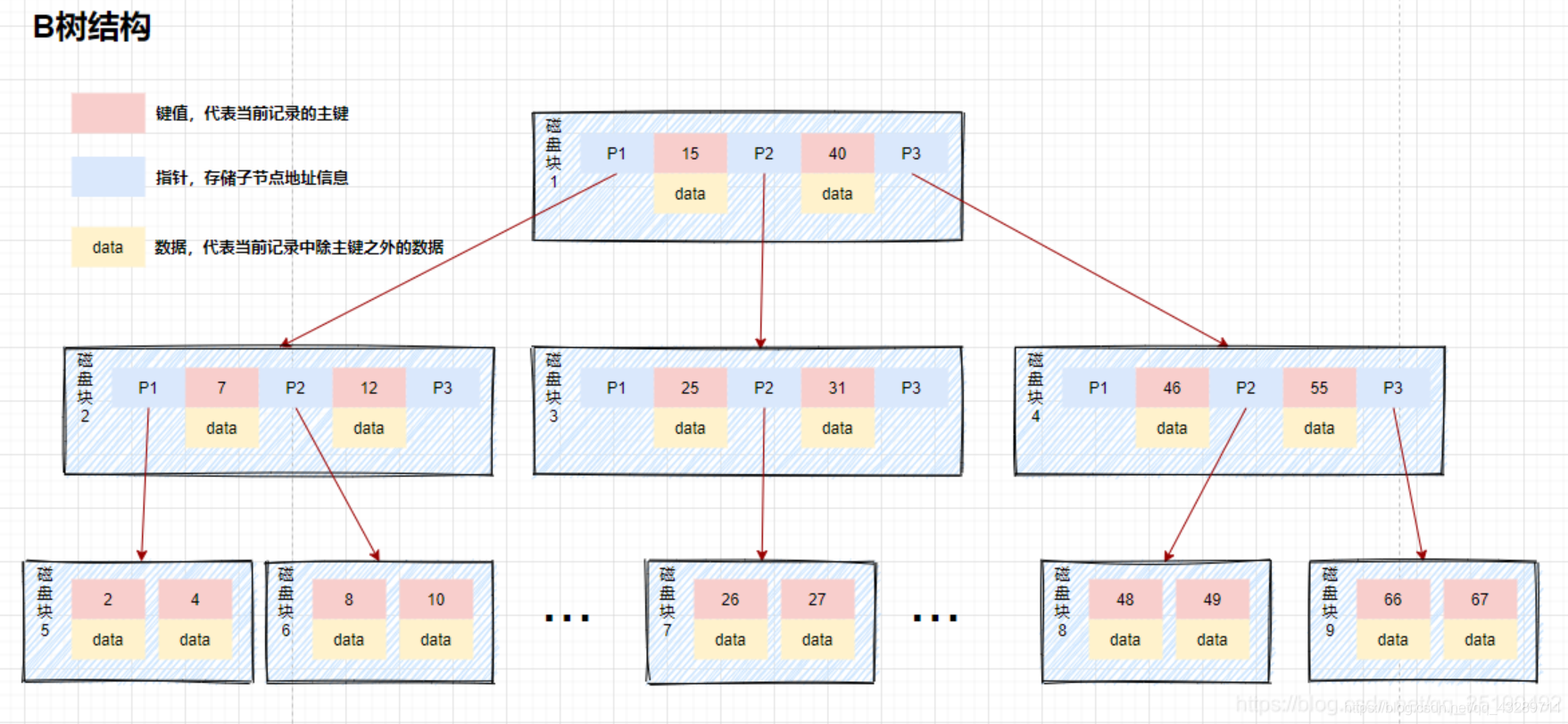
4)B+树:
在B树的基础上,但是非叶子节点一律不存储数据,让所有的非叶子节点只起到一个引路的作用,然后将所有叶子节点用指针连接起来,构成双向链表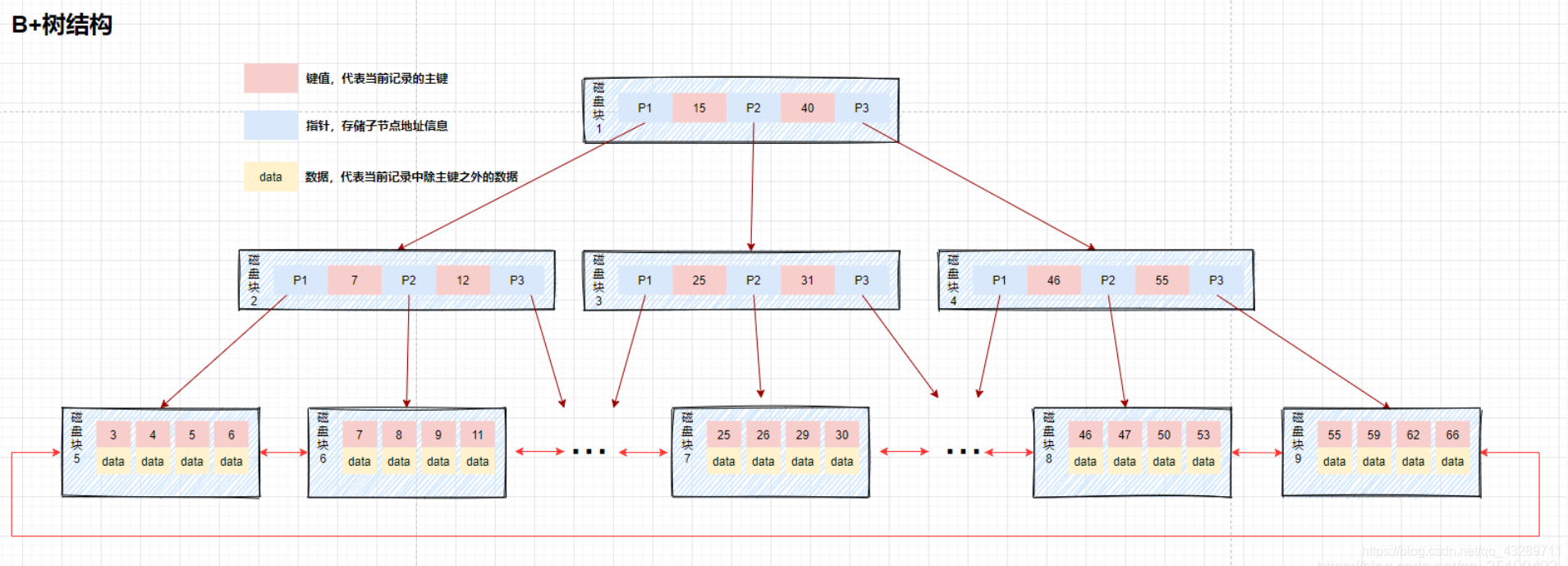
2.使用B+Tree来组建索引
为某个表建立一个索引,其实就是建立一个B+Tree的数据结构,方便在查询时,能够使用O(logn)的时间复杂度。
单值查询:
在查询能用到索引时,就可以避免全表搜索,而是先将索引项与B+Tree各层节点比较,小于走左边,大于等于走右边,一直走到叶子节点拿数据。这对应那些查询条件为=的查询
批量查询:
如果是批量连续的数据,那么就可以利用底层的双向链表直接拿去下一个数据,而不是逐个去从根节点来查找,这很适合那些查询条件里带有>,<等范围比较符的查询
同时应该注意到,如果面对!=或者<>符号,那么索引就无从查起,因为从根节点开始,不知道该走左边还是右边
3.MyISAM的索引
MyISAM只分为主键索引和辅助索引
主键索引
每个主键字段都默认建立的索引,它的实现方式就是上面的B+Tree,不过MyISAM是索引和数据分开存放的,B+Tree的叶子节点里存放的值是数据的地址
辅助索引
除主键索引外,其他列建立起来的索引都是辅助索引,其建立形式与主键索引并无差别
4.InnoDB的索引
InnoDB只分为聚簇索引(主键索引)和辅助索引
聚簇索引(主键索引)
InnoDB的主键索引称作聚簇索引,InnoDB不一样,它将数据的值原原本本的存放在叶子节点中,所以根据聚簇索引查询到叶子节点就是直接拿到了各个记录的值
辅助索引
除聚簇索引外,其他列建立起来的索引都是辅助索引,但是和聚簇索引不同,辅助索引的叶子节点存放的是主键索引值,所以根据辅助索引得到主键后还需要再查一次。
当然可以设置成直接在辅助索引下拿值,也就是建立覆盖索引
5.更多功能的索引
组合索引(联合索引)
结合最左匹配原则使用效果最好
一次对多个列建立索引,其底层结构及查询过程如下: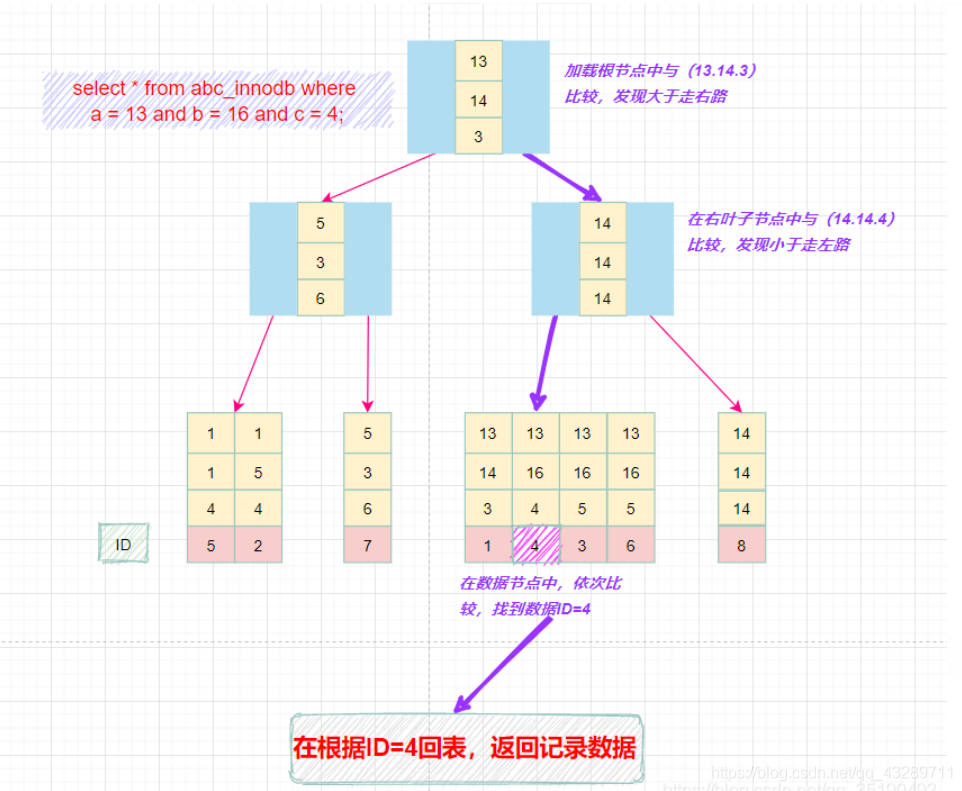
覆盖索引
在InnoDB的辅助索引里,明显查到主键再回表查增加了查询时间,覆盖索引就是为了避免这样的情况,让辅助索引像主键索引一样。但是这样会大大的增加存储成本。
五、提高性能
1.大表优化
当单表的记录数过大时,会严重影响CRUD的性能,可以从以下思路入手优化
- 查询要带限制条件,不能一个查询没有限制条件,这样的查询很消耗资源,比如用户要浏览所有的订单,我们大可以先只给他显示一个月的
- 读写分离,SQL语句分为查询类和更新类,主库负责写,从库负责查
- 垂直分区,一张表的信息要足够单一,不要将关联不强的信息放在同一张表
- 水平分区,把一个表存在好几个库里面,达成分布式存储
2.SQL优化
很多时候,查询慢很大部分原因是我们的SQL语句写的太烂了
- 只取自己需要的字段,不要滥取,
SELECT *是不可行的 - 要能够用得上索引,避免全表扫描。这就有很多细节了,诸如条件里不能有
!=,<>,左边不要有函数操作id-4=3这样的操作,条件里不要有or而是应该用union或者unionall来得到正确结果 - like语句不要
%abc%这样,而应该abc%,除非是全文索引 - 使用联合索引,一定注意最左匹配原则
- 应考虑在 where 及 order by 涉及的列上建立索引,尽量避免全表扫描。
SQL优化远不止这些,可以看下这个书写高质量SQL的文章:
书写高质量SQL的30条建议
3.数据库连接池
和我们Java的线程池类似,都是池化设计的思想。
数据库连接的本质是socket连接,而我们在每执行一条SQL就就新建和销毁一个连接,这是很消耗资源的,尤其是那些经常使用的重复度很高的SQL,我们大可以将这些连接缓存起来,等到心得SQL请求过来时再从缓存中直接拿出来用。
在连接池中,创建连接后,将其放置在池中,并再次使⽤它,因此不必建⽴新的连接。如果所有连接都被使用,则会建⽴⼀个新连接并将其添加到池中。
本博客所有文章均采用 CC BY-SA 4.0 协议,除友链外 ,转载请注明出处!